This post will go through using Visual Studio Code (VS Code) as the “native” file editor for Linux by leveraging the Windows Subsystem for Linux 2 (WSL2). Cross-platform development between Windows and Linux has been made simpler over the years since the introduction of Windows Subsystem for Linux. Gone are the days of dual boots, hypervisor VMs, or multiple machines to get started in developing between Windows and Linux. However, until WSL2 I continued to use both Windows and Linux native editors for each environment. In Windows it is Visual Studio or VS Code and in Linux it is VIM or nano.
With WSL2 it is now possible to edit the direct Linux filesystem files from within VS Code in Windows which reduces the need for VIM/nano and provides IntelliSense for known file types. A very transparent editing experience with high productivity.
The intent of this post is not to compare VIM to VS Code or claim one is better than the other. Code/text editors strike passion in anyone who does any type of substantial editing, particularly if attempting to convince them there is a better one than what they are using. This passion is fully justified and what is the right editor for one may not be right for someone else. Regardless of editor; Notepad, Notepad++, Word, VS Code, Visual Studio, Eclipse, VI, VIM, nano, etc. if the one you are using makes you productive, then that is the right editor for you. After all, computing was intended to make our lives more productive, not less (a tidbit I sometimes find overlooked in the spirit of innovation).
The problem WSL2 and VS Code has solved, is if we are productive using VS Code based on its capabilities and extensions, such as IntelliSense, Source Code Management, etc., we want that productivity to carry across Windows and Linux filesystems.
WSL2 is a feature of Windows 10 that allows running a full Linux Kernel instance on the same machine utilizing its hypervisor technology, Hyper-V, effectively running a lightweight Linux VM on Windows. Yes, the summary is less than truthful by stating hypervisor VMs are gone. It is still there and the enabling technology for WSL2, however, we do not need to manage it ourselves, thus making us more productive. This virtualization technology enables us to view and edit the Linux filesystems from Windows using VS Code.
Next we will go through the steps of getting WSL2 installed and configured with VS Code integration to see this editing in practice. However, VS Code will not replace VIM, only make its use a little less (for my editing), and if we so choose we can even run VIM within VS Code as will be highlighted in the steps.
3. Open a Command Prompt and list installed WSL subsystems and their versions by typing:
C:\Users\Torben\wsl --list --verbose
4. Optional, I had WSL (v1) instances installed prior to running WSL2. One of these, Ubuntu, was configured for WSL2 by running the following command:
C:\Users\Torben\wsl --set-version Ubuntu 2
5. Using the WSL2 shell, in this case for Ubuntu, log in to the terminal.
6. Enter the following command to install the VS Code Server on Linux and launch VS Code in Windows from the current directory:
$code .
7. VS Code should launch into a WSL session showing the instance, Ubuntu, with a directory and file listing for the current directory.
8. Using VS Code, we can now open and edit the files directly, including a terminal window inside the editor for executing bash commands within Linux.
9. The Ubuntu WSL terminal can now be closed and all file editing and terminal commands can be executed directly within VS Code.
Goodbye VIM? Well, not really. I will continue to use VIM (and nano), particularly when working on systems with no WSL support or Windows. However, getting VS Code extensions and IntelliSense support for known file types while editing them directly on the Linux filesystem is a nice productivity boost.
Should the urge/need be there to continue editing with VIM, we can also perform that action while staying within VS Code using the terminal window. This gives us an editor-in-an-editor experience where changes in VIM shows up in VS Code (and vice versa). (Haven’t found a huge need for it, but pretty neat capability none the less :-))
10. Using the example from step 8, we keep the ‘hosts’ file open in the VS Code editor window and use the bash terminal to edit the same hosts file in VIM
11. Enter a new host entry, ‘piorange’ in VIM
12. Save the change and close VIM
13. Notice the VS Code editor version of the hosts file updates automatically to show the new change ‘piorange’
Enjoy!
Next Steps
Will this work if Windows and Linux are on separate machines and not using WSL2? I don’t know but suspect the answer is no as of this writing, but perhaps someone can confirm. I could see it is a nice-to-have feature, but seems to stretch the intent behind WSL2 of being productive in a closed system loop between Windows and Linux.
This post covers the setup of building container images with Azure DevOps that target x64 and ARM processor architectures and pushes them to Docker Hub registry. This is a continuation of the post, Docker Blazor App on Linux ARM, to support development on x64 and deploy to both x64 and ARM architectures. As described in the previous post, building docker images that targets different processor architectures like x64, ARM, and macOS provides runtime flexibility. However, the build process can be time consuming without automation which will be addressed in this post. Let’s start by reviewing the process for manually targeting x64 and ARM with the following design:
Integration between Windows & Linux Containers on x64 & ARM architectures
Although the source code remain the same, the setup required us to have to manually build the application for each architecture and push the build images to Docker Hub. Dual build and pushes.
This post will evolve the above manual process to an automated process using the following design.
Azure DevOps build automation for multi-processor architectures
Raspbian 32-bit on ARM architecture (Raspberry Pi armv7l or lower)
Description
To distribute an application for use, we need to take a version of the source code and build it on a system processor architecture that it is targeted to run on.
Source Repo
=>
x64 Build Machine (to run on x64 machine)
If we want our application to run on other architectures we need to repeat the build on each build machine that matches the target runtime architecture.
Source Repo
=>
x64 Build Machine (to run on x64 machine)
=>
macOS Build Machine (to run on macOS machine)
=>
ARM Build Machine (to run on ARM machine)
As there is no application code changes between the builds, the activities to build across the multiple architectures is similar and can become tedious to repeat manually.
Time has shown us that we can make and sustain application stability faster if we build and test our code changes incrementally as they occur vs. waiting for multiple changes to have been applied. This means we need to build on each source repo update referred to as Continuous Integration (CI). This best practice introduces a significant increase in build numbers that automation becomes a necessity.
To help regain the time performed in orchestrating each architecture build, we can automate our manual activities by introducing a system orchestrator to act on our behalf.
Source Repo
<=
Orchestrator
=>
x64 Build Machine
<=
Orchestrator
=>
macOS Build Machine
<=
Orchestrator
=>
ARM Build Machine
We have now automated our manual process, but what happens if a 2nd release has to be made before we have finished our first one? We cannot build two (2) releases, r1 & r2, on the same build machine at the same time. This means our orchestrator must hold r2 in a queue until r1 has finished and the build machine becomes available to take the 2nd release.
Source Repo
<=
Orchestrator
Queue (r2)
=>
x64 Build Machine (r1)
<=
Orchestrator
Queue (r2)
=>
macOS Build Machine (r1)
<=
Orchestrator
Queue (r2)
=>
ARM Build Machine (r1)
Queuing is a great option if we have time, but if we want the builds to happen faster we can have r1 and r2 build at the same time by introducing a second build machine for each architecture. This will in effect create a pool of two (2) Build Machines per architecture.
Source Repo
<=
Orchestrator
Queue (0)
=>
x64 Build Machine (r1)
=>
x64 Build Machine (r2)
<=
Orchestrator
Queue (0)
=>
macOS Build Machine (r1)
=>
macOS Build Machine (r2)
<=
Orchestrator
Queue (0)
=>
ARM Build Machine (r1)
=>
ARM Build Machine (r2)
If we get three (3) releases, r1, r2, r3, to build at the same time we can now choose to stay with the current configuration and let r3 wait in the queue while our pools each build r1 or r2. Or, we can add a 3rd build machine to each pool so we can get 3 builds to run concurrently.
This is conceptually the setup that we will use to make a build that target’s multiple architectures automatically. We will cover how these concepts are implemented with Azure DevOps, but they can also be implemented in other toolsets like Atlassian Bamboo orJenkins.
Let’s map the above concepts into Azure DevOps terms.
Concept Term
Azure DevOps Term
Source Repo
=>
Repos
Orchestrator
=>
Pipeline (design & runtime)
Queue
=>
Jobs
Build Machine
=>
Build Agent
Pool
=>
Agent Pool
Azure DevOps includes two (2) additional terms that was not defined in our conceptual model but that will be utilized in the coming steps.
Self Hosted Agent
Refers to a build machine that we are hosting ourselves
Microsoft Hosted Agent
Refers to a build machine that Microsoft is hosting
There is no difference in the build machine concepts, but the self-hosted version can be thought of as a Bring-Your-Own-Build-Machine (BYOBM) vs. Microsoft-hosted is provided by Microsoft. They each come with flexibility and convenience that will be highlighted.
The final part of the orchestrator responsibility is to tell the build agents to push the docker images to the Docker Hub registry. This is performed by the Azure Pipeline when it sends the job activities to the build agents.
The following steps will go through this process targeting x64 and ARM architectures.
Steps
1. Navigate to the root organization of the Azure DevOps instance. In this case https://torben.visualstudio.com and https://dev.azure.com/torben are synonymous.
2. Select ‘Agent Pools’ in left navigation pane and default agent pools should be displayed.
3. Click ‘Add Pool’ and select ‘Self-hosted’ as pool type. Enter ‘Arm32’ to indicate the architecture the build agent(s) will support and remember the name for later use in configuring the build pipeline. Description is optional for the pool. Click ‘Create’ to create the pool for holding build agent instances.
4. Click the ‘Arm32’ agent pool just created to open it.
5. Select the ‘Agents’ tab and click ‘New Agent’ to configure the first build agent.
6. In creating the agent we are downloading the agent application to install on the build machine, in our case Raspberry Pi w/ ARM 32-bit. Select the ‘Linux’ tab, click ‘ARM’ in the left navigation. Instead of downloading the file, we will get the URL to pull it later from the device. Click the ‘Copy’ button to the right of the ‘Download’ button to copy the URL to the clipboard. Save it for later reference. Take a screenshot or make note of the installation instructions to create and configure the agent on the build machine.
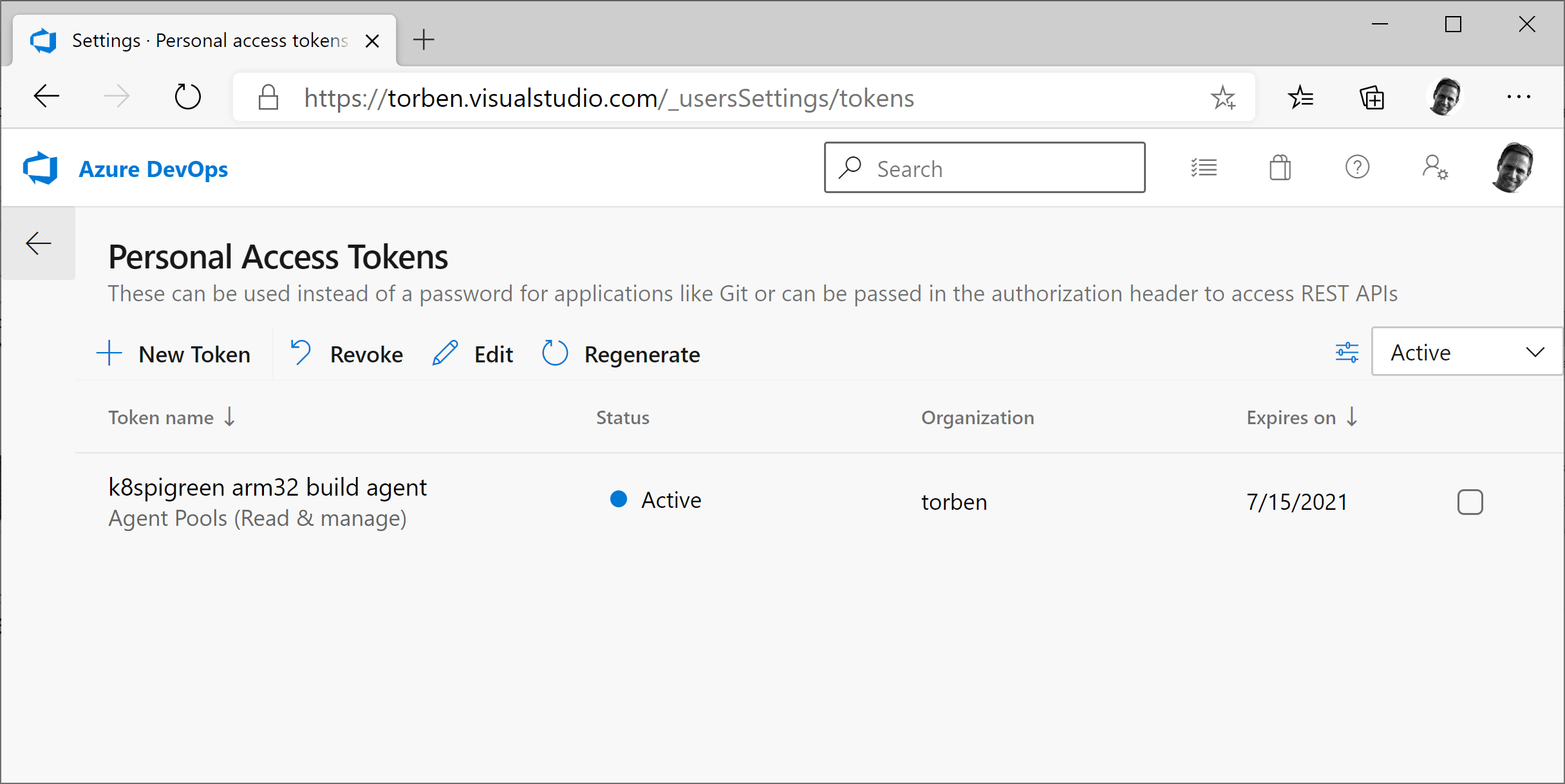
7. Before installing the agent, we need to also get credentials, an access token, that will allow the agent to contact Azure DevOps. This is required because instead of Azure DevOps connecting to each agent, each agent will instead connect to Azure DevOps and register itself to an Agent Pool. Click the ‘User Settings’ next to the user profile and select ‘Personal access tokens’
8. Click ‘New Token’ on the Personal Access Tokens screen.
9. Enter a name that describes what this access token will be used for. In this example we use ‘<raspberry pi name> <agent pool name> build agent’ for a naming convention that will, hopefully, help us remember that this token is used on a build agent and we can identify the machine and pool it was assigned. Select the organization that this token will have access to, in this case ‘torben’. Security best-practices ensure that we rotate the access token periodically and provides the option for a ’30/60/90/custom’ day interval. In this example, a custom date is selected for ‘7/15/2021’ where the token will expire.
10. Click ‘Show all scopes’ and check ‘Read & Manage’ under the Agent Pools scope. Click ‘Create’ and copy the access token for use in configuring the build agent. Note: keep the access token in a safe/secret place.
11. We should now see our newly created Personal Access Token (PAT) and are ready to put it to use with our build agent.
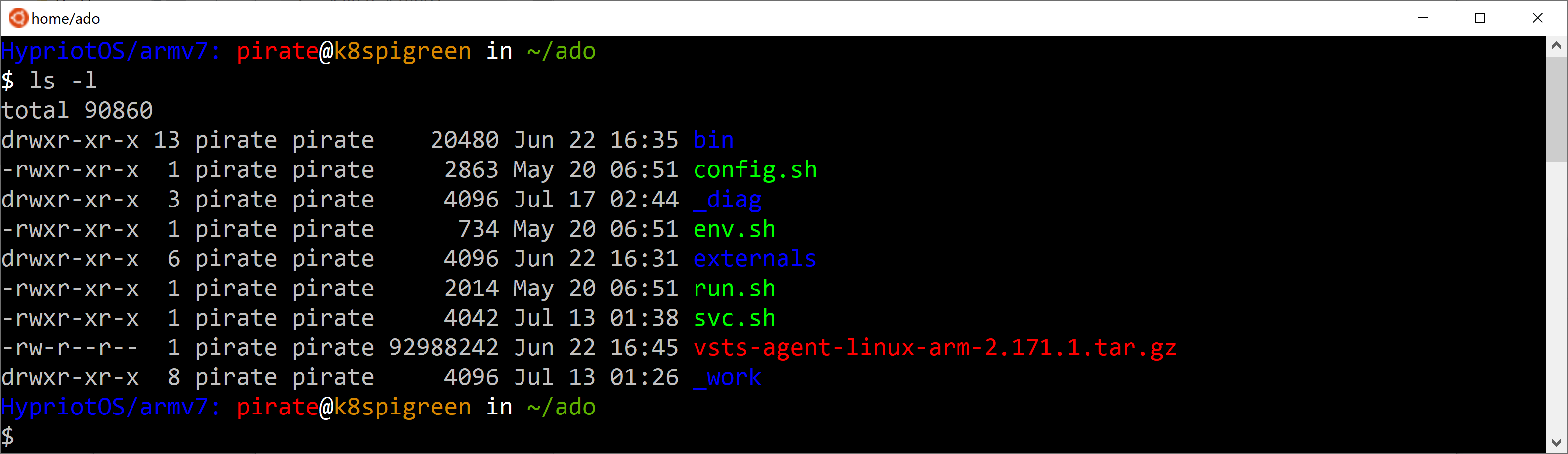
12. Log into Raspberry Pi and execute the following commands.
$ mkdir ado
$ cd ado
$ wget https://vstsagentpackage.azureedge.net/agent/2.171.1/vsts-agent-linux-arm-2.171.1.tar.gz
$ tar -zxvf vsts-agent-linux-arm-2.171.1.tar.gz
$ ls -l
13. Execute the config command to configure the agent.
$ ./config.sh
14. In the Enter Server URL, type ‘https://dev.azure.com/<organization name>’ and hit enter. In the Enter authentication type, hit enter for defaulting to Personal Access Token (PAT). In the personal access token, paste the token copied in step 10 and hit enter.
15. In the Enter agent pool, enter ‘Arm32’ (our Step 3 Agent Pool name) and hit enter. In the Enter agent name, enter <machine name> (k8spigreen) and hit enter.
16. In the Enter work folder, hit enter (taking the default _work) or enter folder name.
17. Execute the run command to start the agent now that configuration is finished.
$ ./run.sh
18. Go back to the Agent Pools under the Organization Settings in Azure DevOps and we should now see our new build agent under the ‘Arm32’ pool, indicating that it is ‘Online’ and ready to take build jobs.
So far so good, we have completed the Cloud-to-On Premise configuration for Azure DevOps to talk to our Raspberry Pi running ARM 32-bit build machine. One area to highlight is that we did not have to open a firewall port for Azure DevOps to reach the build agent on our local network. Instead, the build agent connects securely outbound to Azure DevOps and holds that connection to wait for build jobs getting queued up remotely that it can pull down and build. This design helps lower the hosting complexity of the build agent while keeping the connection secure.
For the Linux x64 architecture build we could follow the same process for creating a self-hosted build agent based on that architecture. However, an alternative option that we will use in this example is to use the Microsoft-hosted build agent provided by Azure DevOps. Easy, the second processor architecture build machine is done 🙂
Now that we have the two (2) build-machines ready we have just one more pre-requisite step before we can configure and run our continuous integration (CI) pipeline. After the docker images are build we want to get them published to a docker registry. In this post, we are using Docker Hub as the registry so we need to configure a connection for Azure DevOps to tell our build agents how to connect to the Docker Hub repository and push the build images.
The Azure DevOps to Docker Hub connection is created via a Service Connection in Azure DevOps.
19. In the Azure DevOps project, go to Project Settings and select Service Connections. Click ‘New Service Connection’ and select Docker Registry.
20. Set the registry type to Docker Hub and enter the Docker Hub ID. Password & Email are optional.
21. Enter a Service connection name that will be used to reference this connection in the pipeline. In this example we name it ‘DockerHub’. Click “Verify and save”.
22. The DockerHub service connection should now be defined and available for pipelines within the project.
Done! We are now ready to put all the steps together in the final build pipeline.
For brevity, the steps for creating the pipeline has been skipped and jumps into the configuration of the multi-processor build configuration.
23. In Azure DevOps, open the Project, select Pipelines and open the pipeline YAML file that should be configured for multi-processor builds.
24. Configure the Build stage to contain two (2) parallel jobs for building both a Linux64 (Microsoft Hosted) and an ARM32 (Self Hosted) docker image and publish them to the Docker Hub registry.
# Docker
# Build a Docker image
# https://docs.microsoft.com/azure/devops/pipelines/languages/docker
trigger:
- master
resources:
- repo: self
variables:
tag: '$(Build.BuildId)'
stages:
- stage: Build
displayName: Build image for Linux64 and ARM32
jobs:
- job: BuildLinux64
displayName: Build Linux64 on Microsoft Hosted
pool:
vmImage: 'ubuntu-latest'
steps:
- task: Docker@2
displayName: Build image for Linux64 on Microsoft Hosted
inputs:
containerRegistry: 'DockerHub'
repository: 'torbenp/helloblazor'
command: 'buildAndPush'
dockerfile: '$(Build.SourcesDirectory)/Hello-Blazor/Hello-Blazor/Dockerfile'
buildContext: '$(Build.SourcesDirectory)/Hello-Blazor/'
tags: |
linux64.$(tag)
linux64
- job: BuildArm32
displayName: Build ARM32 on Self-Host
pool:
name: Arm32
steps:
- task: Docker@2
displayName: Build image for ARM32 on Self-Host
inputs:
containerRegistry: 'DockerHub'
repository: 'torbenp/helloblazor'
command: 'buildAndPush'
dockerfile: '$(Build.SourcesDirectory)/Hello-Blazor/Hello-Blazor/DockerfileArm32'
buildContext: '$(Build.SourcesDirectory)/Hello-Blazor/'
tags: |
arm32.$(tag)
arm32
There are a few configuration items to call out based on our build agent and service connection configurations:
The Job names must be unique to differentiate them but can be named anything, in this case we name by the build processor type:
- job: BuildLinux64
- job: BuildArm32
The pools refer to the “Agent Pools” to be used to build the job. ‘vmImage’ refers to the Microsoft Hosted pool where we will be building on the latest Ubuntu version provided by Azure DevOps. ‘name’ refers to self-hosted, and we provide the pool name created in Step 3.
pool:
vmImage: 'ubuntu-latest'
pool:
name: Arm32
The ContainerRegistry defines the name of the ServiceConnection to the Docker Hub registry that we want the Docker Image pushed to after the build succeeds. The target registry repo will be the same for both architectures.
containerRegistry: 'DockerHub'
To differentiate the architecture images from each other, we use two (2) tags per processor architecture. One tag will define the architecture and build number (linux64.buildNumber and arm32.buildNumber). The second tag defines only the architecture and will constitute the latest build for that processor architecture (linux64 and arm32). Although there are two (2) tags per image, they will both refer to the same image when pushed to the Docker repo. The build numbered version, processor.buildNumber, is considered the immutable version and will not change from build to build. Instead, as the build number changes between builds new image versions will be pushed to the repo. The processor only tag is mutable and will be overwritten for each build so it always refers to the latest image that was build.
25. Click ‘Run’ to start the pipeline build manually.
26. View the build summary for Job status as it will start in the ‘Queued’ state waiting for build agents to accept the job.
27. Once a build agent becomes available it will dequeue the job request and start building which is indicated by the ‘running’ state.
28. Assuming no configuration or compilation errors we should end up in a succeeded state for each job.
29. If we look at the Raspberry Pi console we can see it dequeued from Azure DevOps and ran it successfully on the self-hosted build agent.
30. The final verification is going to the Docker Hub repo to see the two (2) tags that have been created per processor architecture. Notice the build number, 233, for the immutable tags are identical for each processor architecture so we can identify the pairs as additional builds occur. The push times are 1 minute apart per architecture which is caused by the builds happening on different build agents. The Linux64 being posted 1 minute behind the Arm32 is likely caused by the Microsoft hosted infrastructure being shared across several projects and availability of an agent, whereas the Self hosted infrastructure is dedicated and idle.
Next Steps
Several steps can be taken from this point including:
Enable Continuous Integration on the Pipeline – will ensure the build agents are triggered automatically upon a code commit to the source repo.
Add Agents to the Arm32 pool – if more Raspberry Pi’s are required to keep build agents available based on increased build demand.
Add macOS pool – to target a 3rd processor architecture. A third job can be added to the build stage pipeline similar to the Arm32 setup outlined in this post.
Run Agent as a Service – instead of performing step 17 with an interactive ‘run’ command the agent comes with a script for installing it as a service so we can have it running continuously. To install as a service, run the following commands instead of Step 1. (replace ‘vsts.agent.torben.Arm32.k8spigreen.service’ with your servicename)
$ sudo ./svc.sh install
$ sudo systemctl start vsts.agent.torben.Arm32.k8spigreen.service
//Verify service is running (optional)
$ sudo systemctl status vsts.agent.torben.Arm32.k8spigreen.service
As seen in Step 3, build agents are available for many operating systems and processor architectures. The decision between Self-hosted vs. Microsoft hosted is primarily driven on build requirements and availability within the Microsoft hosted landscape. The reduced setup and maintenance requirements makes the Microsoft hosted instance the ideal starting point with the Self hosted option for greatest flexibility.
Blazor provides the ability to create client web apps in C#. It has both server and client runtime options which allow the developer to choose the runtime location that provides the best end-user experience. The server solution utilizes a model-view-controller (MVC) pattern with a persistent WebSocket connection for event processing. This solution lends itself well for creating Single-Page-Applications (SPA) that are heavy in backend compute/storage processing but uses less data for user view/action. For example, running analytics on the backend and visualizing results on the client. Alternatively, the client runtime model utilizes WebAssembly to offload the compute to the client as a Progressive Web Application (PWA) with offline support. This solution is great for high-performance visuals where the client-server latency could adversely impact the user experience, such as in gaming.
This post will create of a Hello-World example of a Blazor Server application. Specifically, how to package the application in a Docker image and deploy it to a Raspberry Pi running Linux on ARM. The development environment will be Visual Studio running Windows on x64 which introduces the following three (3) areas to explore:
Area
Differences
Description
Operating System
Windows vs. Linux
Design-time is Windows targeted for runtime on Linux
Memory Address
32 vs. 64-bit
Design-time is 64-bit operating system targeted for runtime on 32-bit operating system
Architecture
x64 vs ARM
Design-time is x64 architecture targeted for runtime on ARM architecture
A few years ago this would likely have been deemed too complex and unmaintainable to sustain and forced a move to an alternative implementation. However, utilizing two (2) on-premises systems (x64 & ARM) along with two (2) cloud services, this scenario can be accomplished ‘fairly’ easily with the following end-state architecture.
Docker Blazor App designed on Windows x64 and target deployment on Raspberry Pi ARM 32-bit.
Raspbian 32-bit on ARM architecture (Raspberry Pi armv7l or lower)
Description
The first question to answer is why? Building an application to run across multiple operating systems, 32-and-64 bit memory addresses, and different processor architectures sounds more like a research project than any real-life use-case. One answer is the ability in delivering solid code as a developer (yes, there are more use-cases but this post will focus on the developer ability to run and test server-based applications).
When building applications on a laptop targeted for a multi-server runtime environment it can become challenging to verify if the application behaves as expected when considering variables such as network latency, process parallelization, etc. Having a dev-cluster helps mitigate this and having one per developer provides the greatest change isolation. The public cloud has made it convenient and flexible to provision these types of environments quickly. Alternatively, with the introduction of Raspberry Pi and Single Board Computing (SBC) devices it is now possible to create a private cloud with a fairly low capital investment. Thus, the developer loop we will create is as follows:
Developer Laptop (Client) – Local Design-and-Runtime – Windows 10 (64-bit)
==>
Raspberry Pi (Server) – Remote Runtime – Linux Raspbian (32-bit)
Application portability becomes a key requirement for this setup to provide a like-for-like application deployment between the client and server environments. Containerization technologies, such as Docker, is the enabling solution for this requirement. Building an immutable image that can be instantiated easily on different machines while ensuring a consistent dependency configuration is a deployment productivity boost. Although Docker helps bridge the deployment packaging for portability, this scenario has two (2) elements that makes it a little more challenging.
Challenge #1 – Kernel dependency Containerization is an application virtualization technology, but is still dependent on an operating system kernel in order to operate. This kernel is shared across all containers to minimize the container size and memory requirements which means the operating system hosting the container is the base kernel the application must be based on. This means building an application that is based on the Windows kernel will require a Windows host to operate. Vice versa, an application is based on the Linux kernel will require a Linux host to operate.
Thankfully, the Moby Project has helped solve the challenge of running Linux containers on a Windows operating system. This means we can switch the Windows 10 Docker Desktop engine to run Linux containers to verify the container can run locally on Linux before deployment to the server. In the past, this would have created additional dependency problems using the .NET Framework on Linux. But with the introduction of .NET Core, it now includes support for Linux so changing the operating system will not impact the application code.
Challenge #2 – Processor architecture dependency Now the kernel dependency has been solved by utilizing a Linux kernel Docker image with .NET Core we run into a mismatch challenge in processor architectures. If we build the docker image on the Windows laptop based on a Linux amd64 image it will run fine on the client laptop. Unfortunately, running this image on the ARM architecture will cause an image format exception as the processor architectures are not compatible.
standard_init_linux.go:211: exec user process caused "exec format error"
To resolve this compatibility issue we need to have the base image based on the ARM architecture. However, without a hardware emulation package like QEMU, there is no ability to build the application with an ARM architecture image on the x64 architecture.
As we happen to have an ARM based device available, we can use it to build the application natively on the Raspberry Pi. This creates the following flows for building and publishing the application across the two environments.
Windows 10 Laptop
builds
Linux x64 image
Windows 10 Laptop
pushes
Linux x64 Image to Trusted Registry (Docker Hub)
Windows 10 Laptop
pushes
Source Code to Git Repo (Azure DevOps)
Raspberry Pi Server
pulls
Source Code from Git Repo (Azure DevOps)
Raspberry Pi Server
builds
Linux ARM32 image
Raspberry Pi Server
pushes
Linux ARM32 image to Trusted Registry (Docker Hub)
The result will be a single code base with two (2) deployment packages targeting Linux x64 and ARM 32-bit.
Next are the steps to guide through this process.
Steps
1. Launch Visual Studio (Community or higher), Create a new Project and select ‘Blazor App’ in the template.
2. Select ‘Enable Docker Support’ in the options and ‘Linux’ as the target environment.
3. Once the project is open, navigate to the Pages folder and open ‘Index.razor’. Change the default code to the following to add a small amount of code that shows the runtime operating system, memory address, and architecture of the device.
@page "/"
@using System.Runtime.InteropServices;
<h1>Hello, world!</h1>
Welcome to your new app.
<p />
Running on: <b>@Environment.OSVersion (@GetOSBit()-bit on @GetArchitecture() architecture)</b>
<SurveyPrompt Title="How is Blazor working for you?" />
@code
{
private int GetOSBit()
{
return Environment.Is64BitOperatingSystem ? 64 : 32;
}
private string GetArchitecture()
{
switch (RuntimeInformation.OSArchitecture)
{
case Architecture.Arm:
case Architecture.Arm64:
return "ARM";
case Architecture.X64:
return "x64";
case Architecture.X86:
return "x86";
default:
return "unknown";
}
}
}
4. Open the ‘DockerFile’ and verify that the multi-stage build is based on the Linux amd64 images. Note: version number may be different but can be verified in Docker Hub for ASP.NET Core 2.1/3.1 Runtime and .NET Core SDK.
...
FROM mcr.microsoft.com/dotnet/core/aspnet:3.1-buster-slim AS base
WORKDIR /app
EXPOSE 80
EXPOSE 443
FROM mcr.microsoft.com/dotnet/core/sdk:3.1-buster AS build
WORKDIR /src
...
5. By default, Docker Desktop will be configured for Windows Containers. As we targeted Linux in the setup, click the docker icon in the system tray and ‘switch to Linux containers’.
6. Build and Run the application as ‘Docker’ and we should see a screen similar to below that we are running on a Unix compatible operating system (Linux), 64-bit memory addressing and on an x64 architecture.
7. Optional – to see multi-platform capabilities of ASP.NET Core, change the runtime environment from Docker to ‘IIS Express’ in Visual Studio and run the application again. Notice that the operating system now reflects running on Windows 64-bit without any code changes to the application.
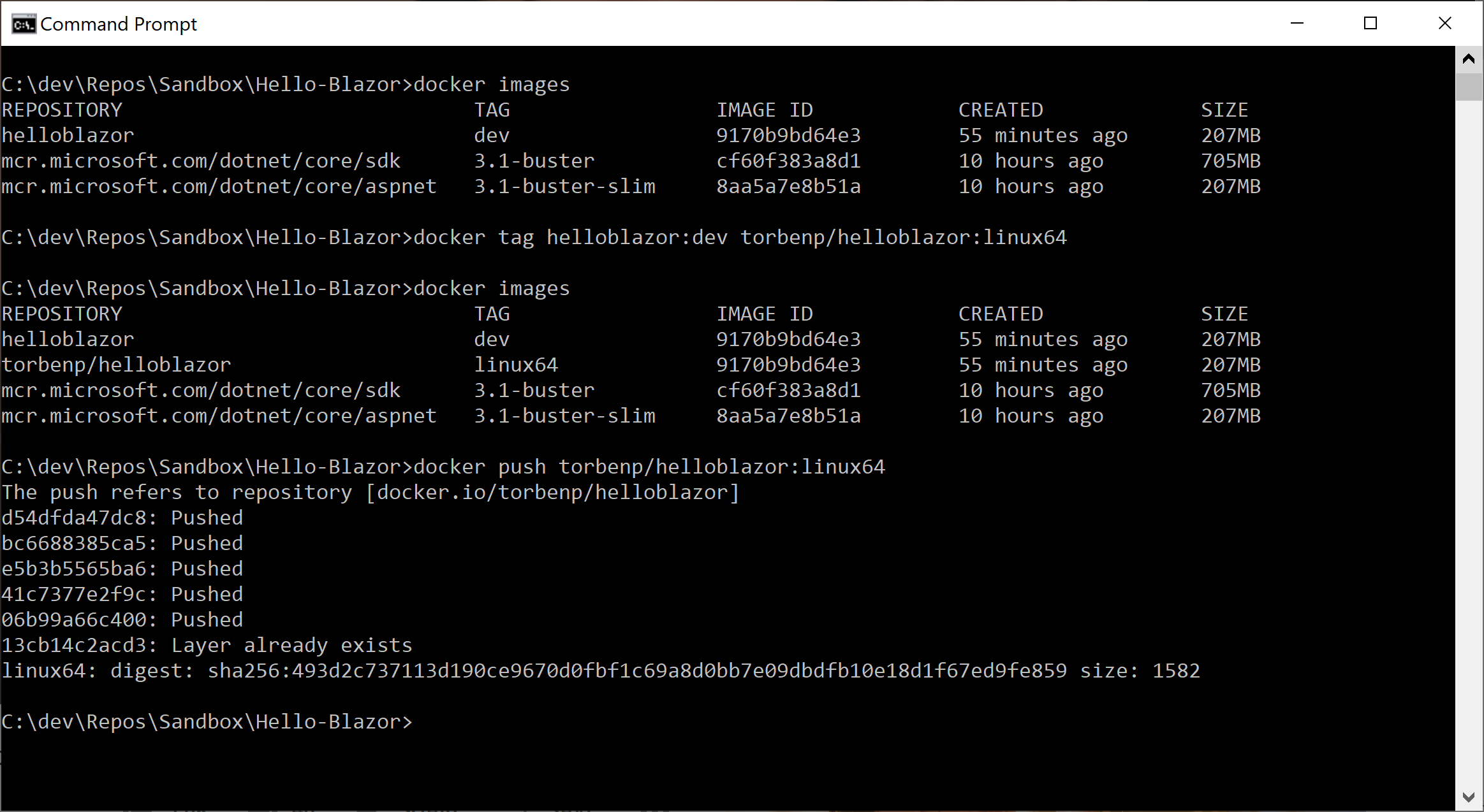
8. We should now have a dev tagged image in our local docker images repository that can be re-tagged for the Docker Hub repo and pushed to upload to Docker Hub.
9. At this point, we can commit and push the source code to Azure DevOps as the source code management (SCM) system. For brevity, this step has been omitted and for the scope of this post could be substituted for any other SCM system, such as GitHub.
10. Let’s turn to our server, Raspberry Pi, and run the Docker image just build, helloblazor:linux64, to see what happens. Note: the image is pulled successfully, but fails to run with the error “exec format error” due to the architecture mismatch.
11. To build the ARM architecture image, we will need to install git, clone the source, and update the Docker multi-stage image to be compatible with ARM 32-bit. The following commands can be executed on the Raspberry Pi.
12. Edit ASP.NET Core and .NET Core SDK images to use arm32v7. In this example, we comment out ‘#’ the previous Linux amd64 images and substitute with arm32v7 images.
...
#FROM mcr.microsoft.com/dotnet/core/aspnet:3.1-buster-slim AS base
FROM mcr.microsoft.com/dotnet/core/aspnet:3.1.5-buster-slim-arm32v7 AS base
WORKDIR /app
EXPOSE 80
EXPOSE 443
#FROM mcr.microsoft.com/dotnet/core/sdk:3.1-buster AS build
FROM mcr.microsoft.com/dotnet/core/sdk:3.1.301-buster-arm32v7 AS build
WORKDIR /src
...
14. We have now completed and verified the recompilation for switching from a x64 64-bit architecture to an ARM 32-bit architecture. The final step remaining is to re-tag and push the new architecture image to Docker Hub repo.
$ docker tag helloblazor:arm32 torbenp/helloblazor:arm32
$ docker push torbenp/helloblazor:arm32
Next Steps
As evidenced by the length of this post, this is a very long (and manual) process to repeat each time we need to make a build. This is where Azure DevOps come in to help automate the Continuous Integration (CI) pipeline of building both 32-and-64-bit versions with x64 and ARM architectures. This will be covered in an upcoming post for targeting multi-processor architectures with Azure DevOps.
For brevity, the post only covered deployment to a single Raspberry Pi instead of a full cluster. The actual runtime deployment of the ARM container image can be scaled into a full mini-cloud deployment by combining multiple Raspberry Pi’s into a container cluster using Kubernetes (K8s) or Swarm as an orchestration engine.
It is also worth mentioning that having a separate device for testing is not always required or needed (although it will likely improve the quality of software delivered). The alternative to having a physical Raspberry Pi device is to utilize hardware emulation with QEMU for multi-processor support.